Every business recognizes the value of data. However, few truly understand the journey it must undergo to become genuinely useful. And even fewer realize the potential challenges that can arise when data come to them as they are, without any transformation.
Yes, in some cases, data do more harm than good, and decision-making may turn into a challenging and even dangerous adventure. This often happens because decisions are based on incomplete, inconsistent, or incorrect data.
That’s why data engineering is something you really need. Although you can’t fully exclude all related risks with data management, you still can cushion the blow through thorough preparatory work which is called data transformation. This process has its steps, intricacies, and challenges, and it’s exactly what we are going to talk about in this article.
Dispelling the Last Doubts About the Necessity of Data Transformation
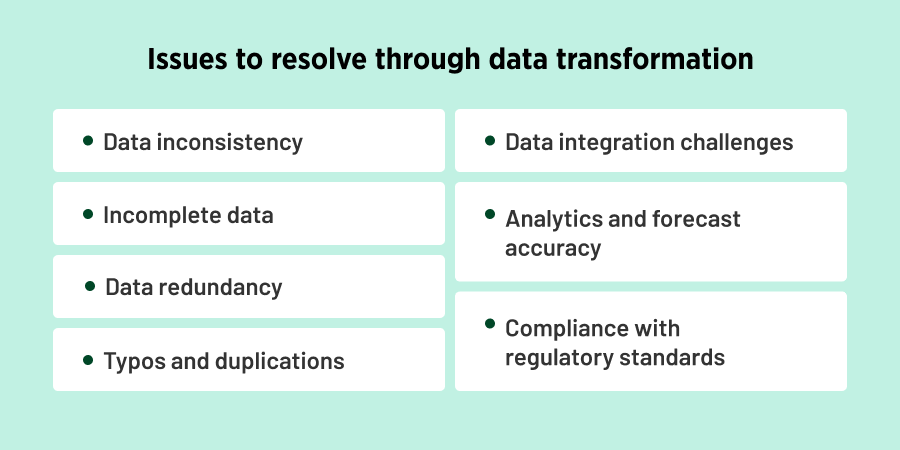
If you still think that data transformation is an unnecessary and expensive waste of time and effort, this part is right for you. Let’s review some examples explaining why using raw data for analytics or predictions is not the best practice to follow, and consider some types of data transformation worth your attention.
Data Inconsistency

If we lived in a perfect world with a single time zone and a unified method of data entry, this problem would never arise. However, reality presents us with 24 time zones and countless variations in how data is recorded. Take dates as an example: Do you write them as DD/MM/YY or MM/DD/YY? Do you separate the components with slashes, dashes, or dots? As you can imagine, different people, systems, and regions have their own conventions.
As you see, even seemingly minor things can make a difference. Mixed dates or incorrectly recorded time may skew analytics or reduce the accuracy of predictions. Sure thing, there are spheres for which these inaccuracies are of little importance. But if we speak about the healthcare sphere, for instance, where a human life is at stake? For example, incorrect timing in medication schedules or misrecorded treatment dates could result in irreparable harm.
Incomplete Data

This is yet another issue that cannot be resolved without proper data transformation techniques. Sometimes, extracted data contains missing entries — such as email addresses, phone numbers, product prices, or physical addresses. Other times, the data exists but is clearly incorrect, like an email missing the “@” symbol.
Working with such flawed data as-is is not an option — it requires intervention. The selection of a data transformation technique to resolve these issues depends on the specific task that is before us. For instance, missing phone numbers might be replaced with placeholders like zeros if no further action is feasible. Alternatively, missing values can sometimes be calculated if sufficient related information is available to infer them accurately. Each scenario demands a tailored solution to ensure the data is complete and usable.
Redundant Data
The opposite issue to insufficient data is redundancy, a common and equally challenging problem to address. For instance, when extracting data manually or via an API, we often end up with hundreds of unnecessary columns that serve no purpose, yet occupy valuable storage space and burden system performance, ultimately slowing it down.
Take building a sales report for a specific year as an example. To create this report, we only need data from that year — no more, no less. However, during extraction, there’s often no way to filter for exactly what we need at the source. This results in a flood of extraneous information.
Our solution here? Conduct data cleansing. This involves carefully identifying and removing redundant data that are irrelevant for analysis. By doing so, we streamline the dataset, ensuring it is concise and ready for comprehensive analytics without unnecessary clutter.
Typos and Duplications

We’re all people inclined to make mistakes, and it’s an absolutely normal thing. When entering data in the system, a person can miss a letter, mix digits up, or duplicate them. Such a risk always has a place to be, that’s why we need to keep this in mind and take some actions so that these typos would affect the analytics.
Imagine, your task is to generate a profit report for the previous year. Upon reviewing the data, you notice a significant spike in financial indicators for this period. This raises a critical question: Is this a genuine growth trend, or does it stem from a data entry error?
Resolving this isn’t straightforward. To determine the truth, you need to compare the results against previous periods. Only by verifying the accuracy of the data can you avoid drawing incorrect conclusions or making decisions based on flawed information. This highlights the importance of thorough validation processes to ensure data integrity.
Compatibility of Data Integration
We need to take note of the fact that data can be extracted from different sources and systems — CRMs, ERPs, Excel reports, Google Sheets — whatever. Obviously, the formats and structure of data stored in these systems may vary as well. They might be in JSON, CSV, or other formats, each requiring its own unique transformation process.
In this scenario, our task is to parse, for instance, a JSON file to prepare the data for further processing. However, performing this manually is far from an efficient solution. Instead, we can use specialized tools or programs that automatically detect the source format and transform it into the desired one quickly and accurately. This ensures seamless and streamlined data preparation for analysis or integration.
Not All Data Can Be Fed to ML Models
When we speak about advanced data analytics and prediction-building, we can’t help but mention ML. The thing to keep in mind here is that machine learning algorithms and models are kind of naughty and don’t accept all data indiscriminately. Therefore, before we feed some data to it, we need to prepare them accordingly.
For instance, it’s not a good option to provide an ML model with text data. Therefore, our task is to transform words into digits. A simple case could involve a dataset indicating an employee’s work mode — either “in the office” or “remotely”.
To optimize the ML algorithm’s efficiency, we encode this text into numeric values, such as 0 for “in the office” and 1 for “remotely.” By applying this data transformation technique, we simplify the processing task for the ML model, enhance its performance, and significantly improve the accuracy of analytics and predictions.
Find out how to Transform Your Business with an Effective Data Analytics Strategy
Regulatory Standards

Last but not least on our list is ensuring compliance with security regulations. Data transformation plays a vital role in safeguarding sensitive information and minimizing the risk of misuse, even in the event of a breach.
By implementing advanced encryption algorithms, sensitive data can be transformed into formats that are extremely difficult, if not impossible, to decode without proper authorization. This process not only protects against unauthorized access but also ensures compliance with data protection standards like GDPR or HIPAA, providing peace of mind for businesses and their customers alike.
Discover about HIPAA-Compliant App Development
Data Transformation Process Explained Step by Step
As you see, data transformation is something you can’t do without, since attempting to use these data as-is can lead to complications, such as misinterpretations, errors in integration, or skewed analysis results. In this section, let’s distinguish the steps of data transformation and figure out what happens at this or that stage and if some of them can be skipped.
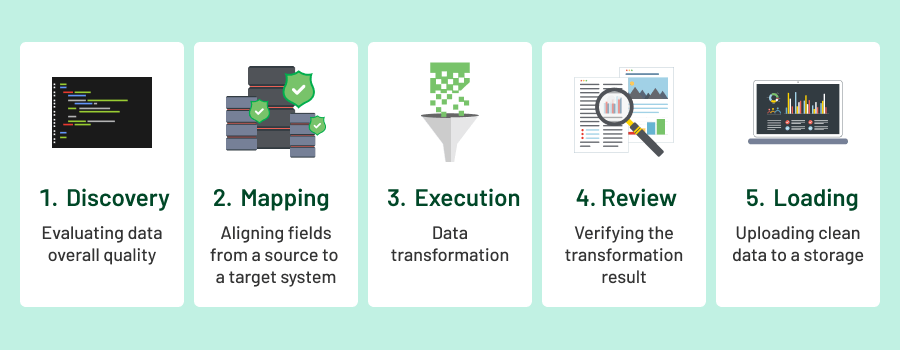
Discovery
This is the first step of data transformation — often the most time- and effort-intensive, taking up to 60-80% of the entire process. Because of this, the temptation to skip it can be really huge, but doing so is highly inadvisable. Here’s why.
During this step, we thoroughly analyze the data structure, their types, characteristics, and overall quality. Essentially, it’s about conducting comprehensive data profiling to determine exactly what needs to be addressed in the transformation process.
At this stage, we uncover various anomalies such as typos, discrepancies, duplications, and missing values. Skipping this step means risking reliance on inaccurate or incomplete data, which can undermine decision-making, distort analytics, and compromise outcomes down the line. Doesn’t it embarrass you? If so, nobody stops you from doing as you wish, just be aware of possible consequences.
Mapping
After addressing data quality and structure and identifying flaws, the next step in the data transformation process is mapping. This stage is about defining how raw data from various sources will be aligned and correlated to fit the desired structure and format. It’s essentially the blueprint that guides how data fields from disparate systems or formats connect and flow into the target model.
Execution
After extensive preparation, we move on to the execution phase. At this stage, we implement the planned actions to refine the data — this includes cleansing, filtering, deduplication, and reformatting — ensuring it aligns with the desired structure and quality standards.
Review and Testing
After completing the data transformation, it might seem like the mission is accomplished. However, not so fast — this is where “trust but verify” comes into play.
The review stage, much like the discovery phase, is crucial despite the temptation to skip it. At this point, we conduct a thorough evaluation to ensure there are no transformation errors and to validate that our business logic is sound. This includes verifying that the mapping was executed accurately and aligned with the intended structure and data formats.
Loading
To turn data into a powerful tool for decision-making, it must be prepared for effective visualization. At the final step of the data transformation process, the refined, structured, and accurate data is uploaded into a Data Lake or Data Warehouse. These centralized repositories act as the foundation for advanced analytics, dashboards, and reporting tools, making it easier to extract actionable insights.
Voilà — your data is now fully ready to assist you with decision-making, strategic planning, and predictive analytics!
Learn the differences between Data Lakes and Data Warehouses
ETL vs. ELT vs. Reverse ETL. Differences Between the Approaches
In the previous section, we outlined a classic data transformation type involving extraction from various sources, transformation, and loading — commonly known as the tried-and-true ETL method. However, the sequence of these steps can vary depending on the specific objectives you aim to achieve.
Let’s now explore ELT and Reverse ETL approaches to better understand their distinctions and purposes.
ELT (Extract-Load-Transform)
As the name suggests, ELT (Extract, Load, Transform) differs from the classic ETL process by loading raw extracted data directly into storage before performing any transformations. This approach is generally considered more flexible as it minimizes the risk of losing valuable data before it reaches a Data Warehouse or Data Lake.
Here’s a simple example: imagine you need to extract data from Google Analytics. There’s always a risk that API limitations could prevent you from retrieving the full dataset. Additionally, external factors like a platform exiting a specific region could render its data completely inaccessible.
Having loaded raw data in your storage you don’t risk losing them as in the case with ETL. However, although the approach is highly scalable and secure, is supported by all cloud architectures, and is a great fit for big data processing, it still has its drawbacks.
The first problem is data proliferation, which makes data management an extremely time- and effort-consuming task. Another challenge lies in the computational powers you need to manipulate your data, which also entails significant expenditures for a powerful cloud.
Read about Cloud Cost Optimization
Reverse ETL

Reverse ETL serves as a natural extension of the ETL and ELT processes and cannot function without one of them. Its essence lies in this key idea.
Once the necessary transformations of data and their enrichments are complete, the data is sent back from the storage to an operational system, such as a CRM or ERP. This enables the enriched data to be seamlessly integrated into business processes.
What advantages does the approach have? Its main benefit is that teams (for example, marketing professionals) can make data-driven decisions and elaborate strategies on the basis of data existing in their system, such as Hubspot or Google Analytics. Directly from these tools, marketers can fine-tune segments or filters that had been configured during the ETL/ELT phase, which eliminates the need to create additional reports or bother with dashboard-building.
Conclusion
Using raw data without applying any data transformation techniques is far from ideal if your goal is progress and growth. While the process of transforming data may be time-intensive and require significant effort, the benefits it brings more than justify the investment. The key is selecting the right strategy, data transformation types, tools, and an experienced team to guide the way.
Our engineers excel at data engineering and transformation, leveraging the latest tools and techniques to deliver results. Reach out to us — we’re ready to help you overcome your data challenges!
Get the conversation started!
About the author