




Data is everywhere and businesses across the globe have an increasing need for solid storage systems that can help run advanced analytics. Unsurprisingly, many are turning to data warehouse implementation to centralize digital information from various sources, improve data quality, and enhance decision-making capabilities.
The global data warehousing market is set to reach $51.18 billion by 2028. So, it’s natural for business leaders to wonder about the potential of these solutions and consider investing in their development to boost performance.
However, before you set out to acquire data warehouse (DWH) software, there are some considerations that may warrant your attention. For instance, you’ll need to decide on your data warehouse architecture.
Of course, your software development partner or internal CTO will likely guide you and advise the most suitable data warehouse design for your unique needs. Nonetheless, it’s still a good idea for business leaders to understand some basics about this topic prior to diving into implementation.
So, in today’s posts, we’ll try to shed some light on the architecture of a data warehouse and discuss the following key points:
- Characteristics of a modern data warehouse
- Main DWH architecture design approaches
- Types of data warehouse architecture
- Components of a DWH architecture
Without further ado, let’s get into it.
Characteristics of a Data Warehouse
First, let’s start by understanding what a data warehouse actually is and how your business can benefit from this technology. In short, a DWH is a centralized repository of digital information from various sources. It is used to support data analysis and business intelligence activities.
Discover the Main Types of Data Analysis in Business
Overall, data warehouses help organizations improve data quality, extract valuable insights, increase security, and generally develop a more comprehensive data management strategy.
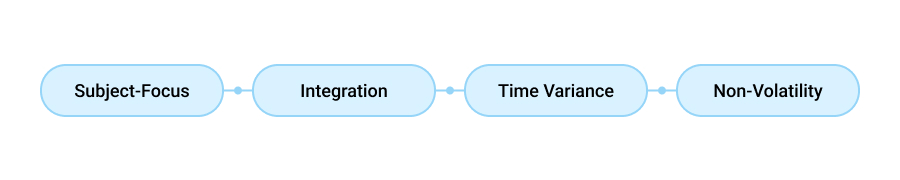
Depending on your unique needs and goals, these tools can be deployed on the cloud or on-premises, but regardless of which you opt for — your data warehouse will have the following four characteristics.
Subject-Focus
A data warehouse is subject-oriented as it delivers information surrounding a particular subject or theme rather than ongoing company operations as a whole. The information it stores might relate to products, customers, sales, revenue, and so on.
Unlike data lakes, warehouses are created with a clear purpose and only store data that is associated with the specific subject that the end-users will be interested in. It eliminates information that may not be useful and only focuses on that which will support the decision-making process.
Find out the Difference Between Data Lakes and Data Warehouses
Integration
Since a data warehouse assembles information from various sources like relational and non-relational databases, it needs to have a common unit of measure for all that integrated data.
Hence, it must maintain consistency in naming conventions, layout, encoding structure, and attribute measures to function effectively.
Time Variance
Data warehouses store centralized data from a concrete time period. As such, they offer insights from a historical point of view and must contain the element of time either explicitly or implicitly.
Another time-variant characteristic of the technology is that data can’t be structured or altered once it has entered a warehouse.
Non-Volatility
Lastly, data warehouses are non-volatile, meaning that previous digital information does not get erased when new data is loaded into the system.
Unlike in other operational applications, delete, update, and insert functions aren’t possible in a warehouse environment. Instead, only data loading and data access operations are performed.

BI for Business
Find out the secrets of how business intelligence boosts operations and what BI tools and practices drive data analysis.
Approaches to Data Warehouse Architecture Design
Now, let’s dive in a little deeper. First, it’s important to understand that there are two approaches to building a data warehouse — top-down and bottom-up. Each has its own pros and cons, and it’s hard to give a clear-cut answer on which is best. Below, we’ll explain each one in more detail.
Bottom-Up Approach
In the bottom-up design, also known as Kimball’s approach, data is extracted from external sources, and data marts for specific business areas are created first. Then, they are integrated into the data warehouse.
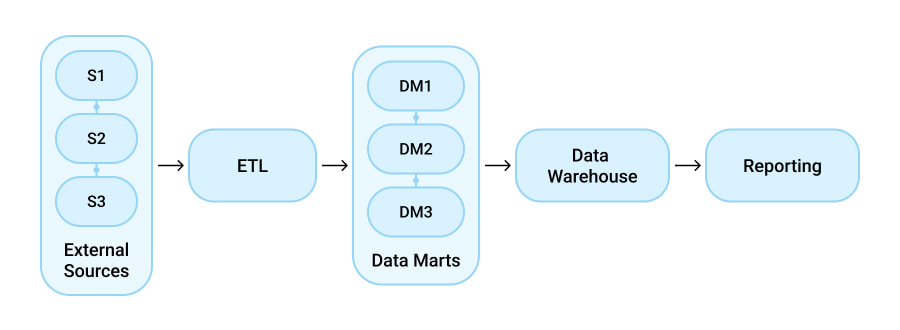
The great thing about this approach is that the initial set-up can be done relatively quickly and at a low cost. Additionally, the data marts that are created first can already provide some reporting capabilities.
However, despite the lower upfront costs, maintenance in this approach is more difficult as the architecture isn’t very flexible. Thus, it can end up costing you more in the long run.
Top-Down Approach
The top-down approach, coined by Bill Inmon, proposes a somewhat different data warehouse architecture design. Here, a DWH is built first and dimensional data marts are developed after.
As a result, the data warehouse focuses on enterprise-wide areas and serves as the single source of truth on relevant business intelligence.
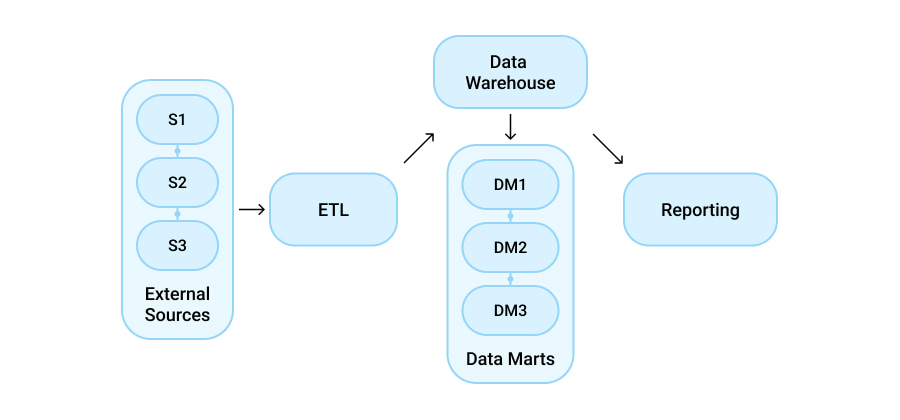
With this approach, a data warehouse ends up being much more flexible than it is with Kimball’s architecture and is easier to maintain. However, it can require significant time, skills, and money to develop.
Types of Data Warehouse Architecture
Regardless of the design approach, there are three types of data warehouse architecture models that you could end up with.
Single-Tier Architecture
This is one of the less popular data warehouse architecture concepts. In a single-tier model, the main objective is to minimize the amount of digital information that is stored and to remove data redundancy.
Single-tier architecture isn’t a good option for organizations with complex data requirements and those dealing with a multitude of data streams. It doesn’t allow for the separation of analytical and transactional processing, which can lead to performance issues.
Two-Tier Architecture
With two tiers, a staging area for all data sources is added to the architecture. It is implemented before the data warehousing layer and helps ensure that all of the digital information loaded into the warehouse is prepared, cleansed, and organized appropriately. This process is known as Extraction, Transformation, and Loading (ETL).
However, as this model separates physical data sources from the warehouse, it is not scalable and can’t support many end users. Hence, it is typically used in smaller companies.
Three-Tier Architecture
Finally, we’ve reached the most widely used type of data warehouse architecture — the three-tier one. As the name suggests, it consists of three distinct layers.
- Bottom Tier. Contains the database server that is used for the extraction of data from various sources.
- Middle Tier. Holds an OLAP server for transforming digital information into a suitable structure for analysis and querying.
- Top Tier. The frontend client layer that contains instruments and API tools for data analysis, reporting, and data mining.
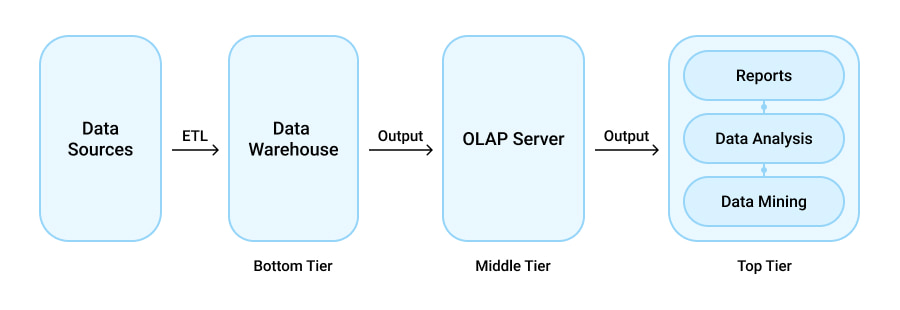
As you can see from the above three-tier data warehouse architecture diagram, it is quite extensive and as such is largely implemented in big-scale, complex systems.
Naturally, it requires an experienced team of data scientists and engineers, as well as business analysts who can help identify your goals and guide you towards successful data warehouse implementation.
Main Components of a Data Warehouse Architecture
Now that you’ve got a high-level overview of the entire data warehousing architecture, it’s time to zero in on some of its key components.

Data Warehouse Database
The database is a central component of any data warehouse architecture. After all, that’s precisely where all the relevant digital information is stored. However, there is more than one option for you to choose from when it comes to databases. In fact, there are four:
- Relational database. A row-centered database that you may use daily. Ex: Microsoft SQL Server.
- Analytics database. Developed specifically for data storage and to facilitate analytics. Ex: Teradata.
- Data warehouse application. Not a storage database per se, but some third-party providers of data management software now also offer hardware for storing digital information. Ex: Oracle Exadata.
- Cloud database. Can be hosted on the cloud so that you can forego the need to set up hardware for your data warehouse. Ex: Amazon Redshift, Google BigQuery, Microsoft Azure SQL.
Of course, you might still be wondering which is suitable for you. Everything depends on your unique needs, but it’s true that companies are increasingly embracing cloud-based data warehouses as they eliminate the need for physical hardware, perform efficiently, and have more flexibility in terms of cost optimization.
Discover how we performed Cloud-to-Cloud Database Migration

ETL Tools
Next up are the ETL tools which help extract data from all kinds of sources, transform it into the correct format, and load it all into the data warehouse. All in all, they usually perform the following functions:
- Eliminate unnecessary data so that it isn’t loaded into the warehouse;
- Anonymize data and help provide data lineage to comply with regulations;
- Remove duplicates that may show up when loading data from multiple data sources;
- Add defaults for missing values.

Metadata
This architecture component is all about offering a framework for data within a warehouse’s database. In essence, it helps construct, preserve, manage, and make use of the data warehouse.
In data warehousing, there are two classifications for metadata:
- Technical metadata. Contains information that is used by developers and managers when developing the warehouse or performing administrative tasks.
- Business metadata. Provides users with easy-to-understand details on the stored data within the warehouse.
Data Marts
A data mart is, in a way, a subdivision of a DWH that is used to segment the digital information within the system into categories for a specific group of users. Typically, a certain data mart pertains to a particular business department or team.
Depending on the complexity of your data warehouse architecture, having data marts within it to partition data between organizational units might be a good idea.

Access Tools
As we’ve already established, a data warehouse’s main goal is to centralize digital information and deliver valuable insights to business leaders. Access tools are precisely what facilitates user interaction with the system. They can be split into four distinct categories:
- Query and reporting tools. Help produce reports in the form of spreadsheets or interactive dashboards.
- Application development tools. Allow for creating tailored reports that go beyond the built-in graphical capabilities.
- Data mining tools. Examine datasets to uncover hidden patterns and correlations in the information stored in the data warehouse.
- OLAP tools. Extract digital information from relational datasets and reorganize it into multidimensional forms. Help run analysis from multiple perspectives.
Get Help With Your Data Warehouse Architecture
The architecture of any application is fundamental to the success and optimal performance of the final solution and data warehouses are no exception. A suitable architecture ensures your system is fast, scalable, secure, and most importantly, that it delivers valuable business intelligence.
As such, data warehouse design is bound to come up often in meetings with the development team. Now, you hopefully have some basic understanding of the key architecture concepts and will be able to stay in the know during any discussions.
If you want to deploy a data warehouse on-premises or to the cloud, or need to modernize an existing solution — don’t hesitate to contact Velvetech.
Our team delivers successful data warehousing services to companies from all kinds of industries. So, we will be happy to discuss your needs and come up with optimal ways for solving the data management challenges you may be facing.
Get the conversation started!
About the author


